Fast Web Scraping With ReactPHP: Download All Images From a Website
Web scraping relies on the HTML structure of the page, and thus cannot be completely stable. When HTML structure changes the scraper may become broken. Keep this in mind when reading this article. At the moment when you are reading this, css-selectors used here may become outdated.
What is Web Scraping?
Have you ever needed to grab some data from a site that doesn’t provide a public API? To solve this problem we can use web scraping and pull the required information out from the HTML. Of course, we can manually extract the required data from a website, but this process can become very tedious. So, it will be more efficient to automate it via the scraper.
Well, in this tutorial we are going to scrape cats images from Pexels. This website provides high quality and completely free stock photos. They have a public API but it has a limit of 200 requests per hour.
Making concurrent requests
The main advantage of using asynchronous PHP in web scraping is that we can make a lot of work in less time. Instead of querying each web page one by one and waiting for responses we can request as many pages as we want at once. Thus we can start processing the results as soon as they arrive.
Let’s start with pulling an asynchronous HTTP client called buzz-react – a simple, async HTTP client for concurrently processing any number of HTTP requests, built on top of ReactPHP:
composer require clue/buzz-reactNow, we are ready and let’s request an image page on pexels:
<?php
require __DIR__ . '/vendor/autoload.php';
use Clue\React\Buzz\Browser;
$loop = \React\EventLoop\Factory::create();
$client = new Browser($loop);
$client->get('https://www.pexels.com/photo/kitten-cat-rush-lucky-cat-45170/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
echo $response->getBody();
});
$loop->run();We have created an instance of Clue\React\Buzz\Browser, then we have used it as HTTP client. The code above makes an asynchronous GET request to a web page with an image of kittens. Method $client->get($url) returns a promise that resolves with a PSR-7 response object.
The client works asynchronously, that means that we can easily request several pages and these requests will be performed concurrently:
<?php
require __DIR__ . '/vendor/autoload.php';
use Clue\React\Buzz\Browser;
$loop = \React\EventLoop\Factory::create();
$client = new Browser($loop);
$client->get('https://www.pexels.com/photo/kitten-cat-rush-lucky-cat-45170/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
echo $response->getBody();
});
$client->get('https://www.pexels.com/photo/adorable-animal-baby-blur-177809/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
echo $response->getBody();
});
$loop->run();The idea is here the following:
- make a request
- get a promise
- add a handler to a promise
- once the promise is resolved, process the response
So, this logic can be extracted to a class, thus we can easily request many URLs and add the same response handler for them. Let’s create a wrapper over the Browser.
Create a class called Scraper with the following content:
<?php
use Clue\React\Buzz\Browser;
use Psr\Http\Message\ResponseInterface;
final class Scraper
{
private $client;
public function __construct(Browser $client)
{
$this->client = $client;
}
public function scrape(string ...$urls)
{
foreach ($urls as $url) {
$this->client->get($url)->then(
function (ResponseInterface $response) {
$this->processResponse((string) $response->getBody());
});
}
}
private function processResponse(string $html)
{
// ...
}
}We inject Browser as a constructor dependency and provide one public method scrape(array $urls). Then for each specified URL we make a GET request. Once the response is done we call a private method processResponse(string $html) with the body of the response. This method will be responsible for traversing HTML code and downloading images. The next step is to inspect the received HTML code and extract images from it.
Crawling the website
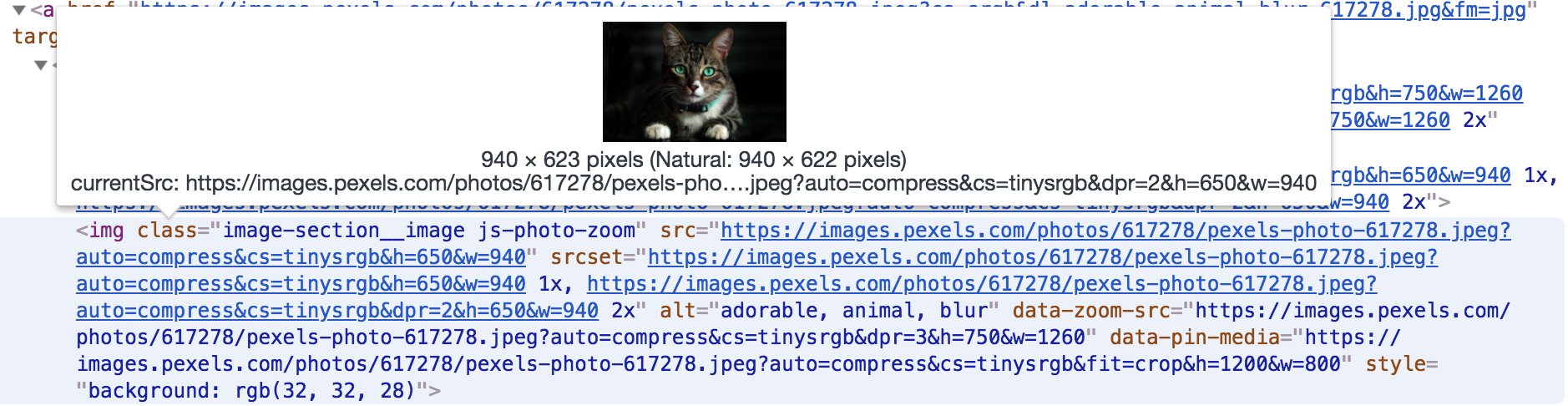
At this moment we are getting only HTML code of the requested page. Now we need to extract the image URL. For this, we need to examine the structure of the received HTML code. Go to an image page on Pexels, right click on the image and select Inspect Element, you will see something like this:

We can see that img tag has class image-section__image. We are going to use this information to extract this tag out of the received HTML. The URL of the image is stored in the src attribute:
For extracting HTML tags we are going to use Symfony DomCrawler Component. Pull the required packages:
composer require symfony/dom-crawler
composer require symfony/css-selectorCSS-selector for DomCrawler allows us to use jQuery-like selectors to traverse the DOM. Once everything is installed open our Scraper class and let’s write some code in processResponse(string $html) method. First of all, we need to create an instance of the Symfony\Component\DomCrawler\Crawler class, its constructor accepts a string that contains HTML code for traversing:
<?php
use Clue\React\Buzz\Browser;
use Psr\Http\Message\ResponseInterface;
use Symfony\Component\DomCrawler\Crawler;
final class Scraper
{
// ...
private function processResponse(string $html)
{
$crawler = new Crawler($html);
}
}To find any element by its jQuery-like selector use filter() method. Then method attr($attribute) allows to extract an attribute of the filtered element:
<?php
use Clue\React\Buzz\Browser;
use Psr\Http\Message\ResponseInterface;
use Symfony\Component\DomCrawler\Crawler;
final class Scraper
{
// ...
private function processResponse(string $html)
{
$crawler = new Crawler($html);
$imageUrl = $crawler->filter('.image-section__image')->attr('src');
echo $imageUrl . PHP_EOL;
}
}Let’s just print the extracted image URL and check that our scraper works as expected:
<?php
// index.php
require __DIR__ . '/vendor/autoload.php';
require __DIR__ . '/Scraper.php';
use Clue\React\Buzz\Browser;
$loop = \React\EventLoop\Factory::create();
$scraper = new Scraper(new Browser($loop));
$scraper->scrape('https://www.pexels.com/photo/adorable-animal-blur-cat-617278/');
$loop->run();When running this script it will output the full URL to the required image. Then we can use this URL to download the image. Again we use an instance of the Browser and make a GET request:
<?php
use Clue\React\Buzz\Browser;
use Psr\Http\Message\ResponseInterface;
use Symfony\Component\DomCrawler\Crawler;
final class Scraper
{
// ...
private function processResponse(string $html)
{
$crawler = new Crawler($html);
imageUrl = $crawler->filter('.image-section__image')->attr('src');
$this->client->get($imageUrl)->then(
function(ResponseInterface $response) {
// store an image on disk
});
}
}The response arrives with the contents of the requested image. Now we need to save it on disk. But take your time and don’t use file_put_contents(). All native PHP functions that work with a file system are blocking. It means that once you call file_put_contents() our application stops behaving asynchronously. The flow control is being blocked until the file is saved. ReactPHP has a dedicated package to solve this problem.
Saving files asynchronously
To process files asynchronously in a non-blocking way we need a package called reactphp/filesystem. Go ahead and pull it:
composer require react/filesystemTo start working with the file system create an instance of Filesystem object and provide it as a dependency to our Scraper. Also, we need to provide a directory where to put all downloaded images:
<?php
// index.php
require __DIR__ . '/vendor/autoload.php';
require __DIR__ . '/Scraper.php';
use Clue\React\Buzz\Browser;
use React\Filesystem\Filesystem;
$loop = \React\EventLoop\Factory::create();
$scraper = new ScraperForImages(
new Browser($loop), Filesystem::create($loop), __DIR__ . '/images'
);
$scraper->scrape('https://www.pexels.com/photo/adorable-animal-blur-cat-617278/');
$loop->run();Here is an updated constructor of the Scraper:
<?php
use Clue\React\Buzz\Browser;
use Psr\Http\Message\ResponseInterface;
use React\Filesystem\FilesystemInterface;
use Symfony\Component\DomCrawler\Crawler;
final class Scraper
{
private $client;
private $filesystem;
private $directory;
public function __construct(Browser $client, FilesystemInterface $filesystem, string $directory)
{
$this->client = $client;
$this->filesystem = $filesystem;
$this->$directory = $directory;
}
// ...
}Ok, now we are ready to save files on disk. First of all, we need to extract a filename from the URL. The scraped URLs to the images look like this:
https://images.pexels.com/photos/4602/jumping-cute-playing-animals.jpg?auto=compress&cs=tinysrgb&h=650&w=940 https://images.pexels.com/photos/617278/pexels-photo-617278.jpeg?auto=compress&cs=tinysrgb&h=650&w=940
And filenames for these URLs will be the following:
jumping-cute-playing-animals.jpg
pexels-photo-617278.jpeg
Let’s use a regular expression to extract filenames out of the URLs. To get a full path to a future file on disk we concatenate these names with a directory:
<?php
preg_match('/photos\/\d+\/([\w-\.]+)\?/', $imageUrl, $matches); // $matches[1] contains a filename
$filePath = $this->directory . DIRECTORY_SEPARATOR . $matches[1];Once we have a path to a file we can use it to create a file object:
<?php
$file = $this->filesystem->file($filePath);This object represents a file we are going to work with. Then call method putContents($contents) and provide a response body as a string:
<?php
$file = $this->filesystem->file($filePath);
$file->putContents((string)$response->getBody());That’s it. All asynchronous low-level magic is hidden behind one simple method. Under the hood, it creates a stream in a writing mode, writes data to it and then closes the stream. Here is an updated version of method Scraper::processResponse(string $html):
<?php
use Clue\React\Buzz\Browser;
use Psr\Http\Message\ResponseInterface;
use React\Filesystem\FilesystemInterface;
use Symfony\Component\DomCrawler\Crawler;
final class Scraper
{
// ...
private function processResponse(string $html)
{
$crawler = new Crawler($html);
$imageUrl = $crawler->filter('.image-section__image')->attr('src');
preg_match('/photos\/\d+\/([\w-\.]+)\?/', $imageUrl, $matches);
$filePath = $matches[1];
$this->client->get($imageUrl)->then(
function(ResponseInterface $response) use ($filePath) {
$this->filesystem->file($filePath)->putContents((string)$response->getBody());
});
}
}We pass a full path to a file inside the response handler. Then, we create a file and fill it with the response body. Actually, the whole scraper is less than 50 lines of code!
Note: at first, create a directory where you want to store files. Method
putContents()only creates a file, it doesn’t create folders to a specified filename.
The scraper is done. Now, open your main script and pass a list of URLs to scrape:
<?php
// index.php
<?php
require __DIR__ . '/../vendor/autoload.php';
require __DIR__ . '/ScraperForImages.php';
use Clue\React\Buzz\Browser;
use React\Filesystem\Filesystem;
$loop = \React\EventLoop\Factory::create();
$scraper = new ScraperForImages(
new Browser($loop), Filesystem::create($loop), __DIR__ . '/images'
);
$scraper->scrape(
'https://www.pexels.com/photo/adorable-animal-blur-cat-617278/',
'https://www.pexels.com/photo/kitten-cat-rush-lucky-cat-45170/',
'https://www.pexels.com/photo/adorable-animal-baby-blur-177809/',
'https://www.pexels.com/photo/adorable-animals-cats-cute-236230/',
'https://www.pexels.com/photo/relaxation-relax-cats-cat-96428/',
);
$loop->run();The snippet above scraps five URLs and downloads appropriate images. And all of this is being done fast and asynchronously.
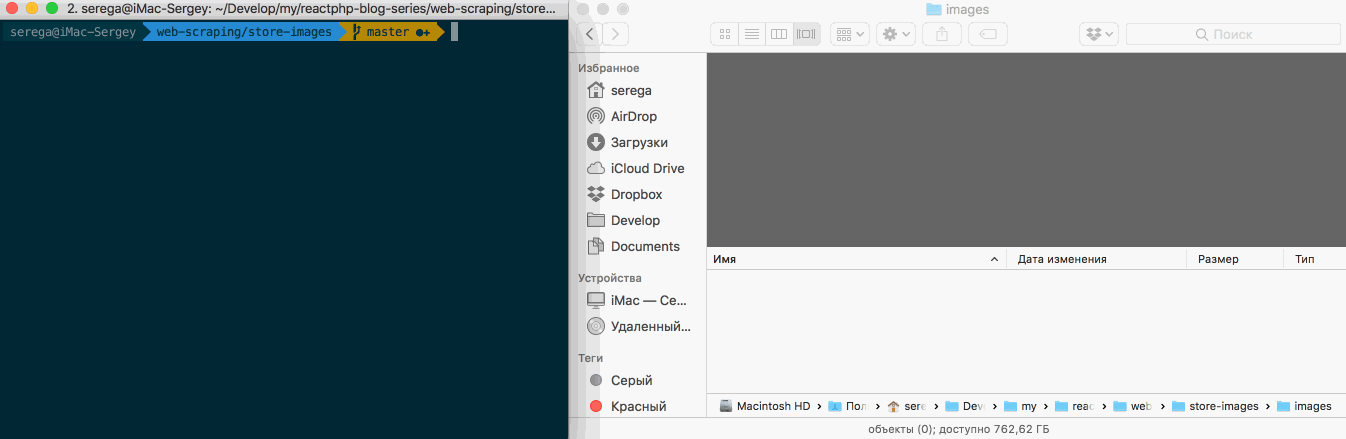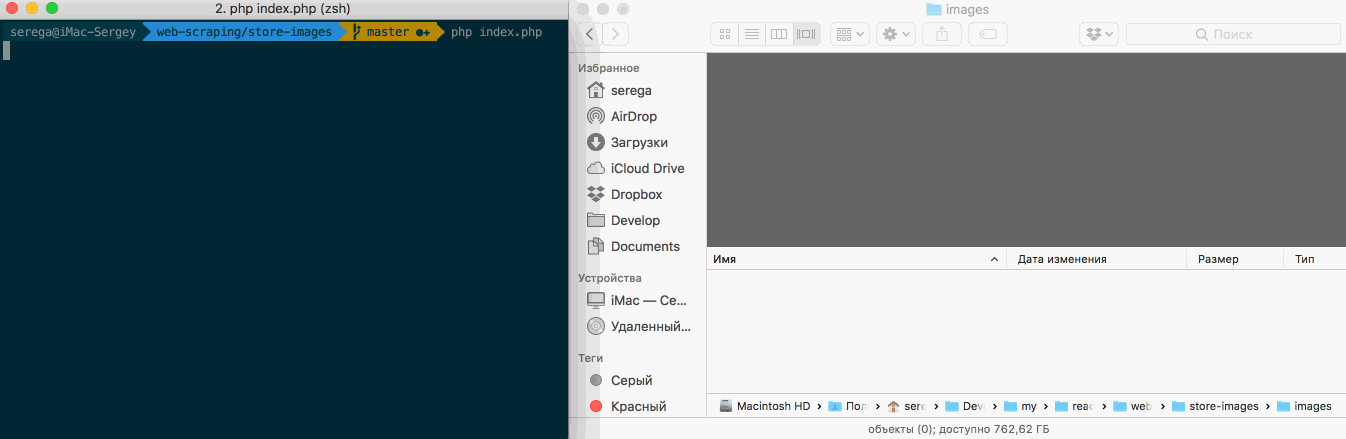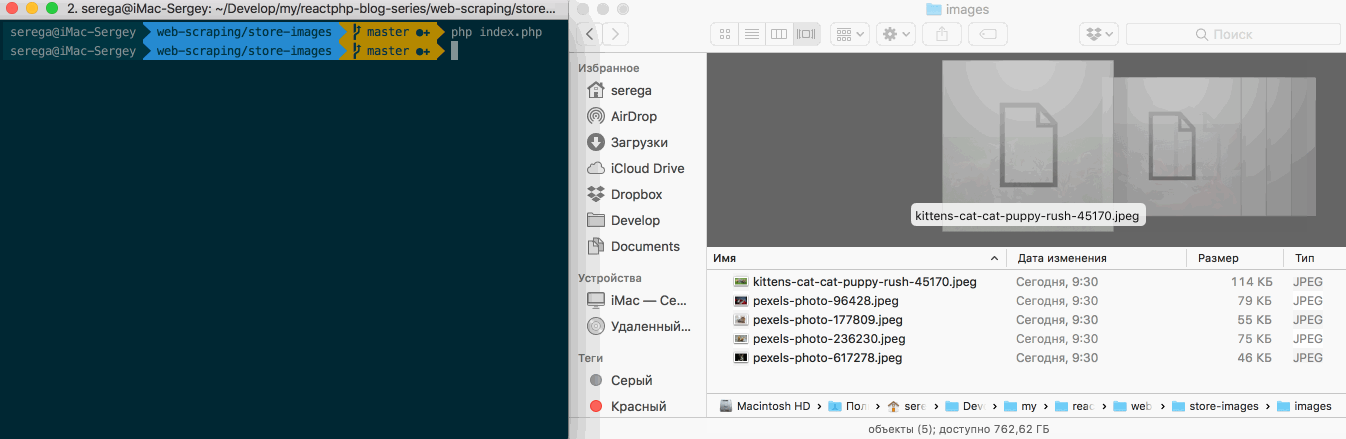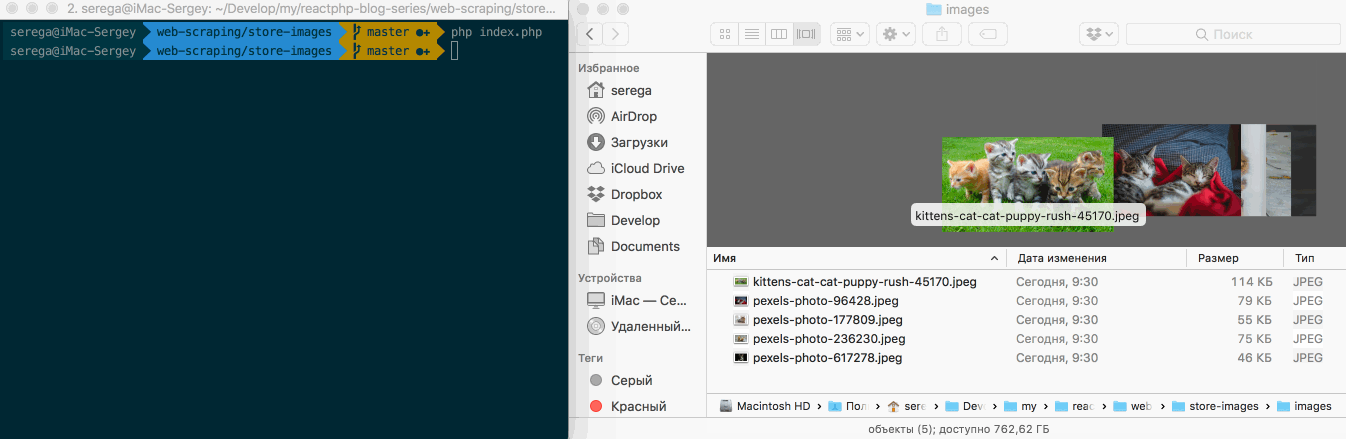
Conclusion
In the previous tutorial, we have used ReactPHP to speed up the process of web scraping and to query web pages concurrently. But what if we also need to save files concurrently? In an asynchronous application we cannot use such native PHP function like file_put_contents(), because they block the flow, so there will be no speed increase in storing images on disk. To process files asynchronously in a non-blocking way in ReactPHP we need to use reactphp/filesystem package.
So, in around 50 lines of code, we were able to get a web scraper up and running. This was just a tiny example of something you could do. Now that you have the basic knowledge of how to build a scraper, go and try building your own one!
I have several more articles on web scraping with ReactPHP: check them if you want to use proxy or limit the number of concurrent requests.
You can find examples from this article on GitHub.
This article is a part of the ReactPHP Series.
Learning Event-Driven PHP With ReactPHP
The book about asynchronous PHP that you NEED!
A complete guide to writing asynchronous applications with ReactPHP. Discover event-driven architecture and non-blocking I/O with PHP!
Minimum price: 5.99$